Just In 3 Clicks!
Why Most AI Initiatives in Retail Fail – And What the Winners Are Doing Differently
Every vendor at ShopTalk Vegas is selling an AI revolution. Almost none of them are talking about why those revolutions actually fail. You are being promised a future where autonomous agents handle merchandising, hyper-personalized recommendation engines drive up average order value, and conversational search makes finding products frictionless.
Retailers are investing heavily in these AI layers. Yet, back at the office, the results are deeply underwhelming.
You plug in a state-of-the-art model, but your search still can’t differentiate between a “light blue summer dress” and a “navy winter coat.” Your generative AI agent hallucinates product specs. Your recommendation engine suggests out-of-stock items.
The counterintuitive premise that no one at the vendor booths wants to admit is this: the AI isn’t your problem. The models are fine. The algorithms are incredibly capable. What you are experiencing is an honest, structural failure of the foundation those models sit upon. This is a diagnosis of what is actually broken in retail tech stacks today, and exactly how the top percentile of e-commerce operators are fixing it.
The Retail AI Gap Is Real – and Widely Misdiagnosed
Industry data and private boardroom conversations share a grim consensus: the vast majority of AI retail initiatives underperform their initial expectations.
When you look at the metrics and see AI search ecommerce underperforming, the immediate instinct is to blame the visible layer. You blame the model for not being “trained” enough. You blame the vendor for overpromising. You blame your integration strategy.
But the actual root cause of exactly why AI retail fails is hiding deeper in your stack: the fragmented, incomplete, and chaotic product data underneath the AI layer.
Consider what happens when a sophisticated search agent pulls from an inconsistent catalog. If one supplier provided the color as “Midnight” in a text field, another provided “Blue” in a dropdown, and a third provided no color data at all, the AI has no universal truth to draw from. It cannot map the customer’s intent to your inventory. An AI model is a high-performance engine, but if you pump contaminated fuel into it, the engine will inevitably sputter and stall.
What “Broken Product Data” Actually Looks Like in Practice
To understand the fix, we have to translate the abstract concept of “bad data” into the concrete operational pain points your e-commerce and ops teams deal with every single day. If you are an enterprise retail leader, “broken product data” looks like this:
- The Ingestion Nightmare: Suppliers don’t care about your taxonomy. They send data in different formats every time – chaotic Excel sheets, unstructured PDFs, raw XML feeds, or proprietary API outputs.
- The Channel Conflict: Product content cannot be uniform. What works on your Shopify storefront will get rejected by Amazon’s strict character limits, and both differ wildly from the requirements of niche marketplaces.
- The Manual Cleanup Loop: Before every major launch or seasonal catalog update, your ops team loses weeks to manual spreadsheet wrangling, data normalization, and copy-pasting just to make the listings presentable.
- The Onboarding Bottleneck: Adding new suppliers does not scale. Because of the manual mapping required, onboarding your 10th supplier takes exactly as much time and effort as onboarding your first.
- No Single Source of Truth: Your teams are managing by exception rather than by rule, frantically fixing errors as they pop up on live channels rather than relying on a centralized, trusted data hub.
Why This Is a Structural Problem, Not a Process Problem
When confronted with these operational bottlenecks, many retailers assume they just need to enforce better processes or hire more merchandisers. But this is a structural problem.
The immediate reflex is often to evaluate your core systems, leading to the classic PIM vs middleware debate. But traditional PIM (Product Information Management) systems are essentially just storage lockers. They store data beautifully, but they do not inherently transform, clean, or syndicate it. If you dump messy supplier feeds into a PIM, you just have a very expensive, well-organized database of bad data.
Furthermore, most internal tools and legacy scripts were built to solve the product data management problem as it existed five years ago. They were not built for today’s scale, nor were they built for the explosive complexity of multi-channel syndication.
The critical gap in your tech stack isn’t in the storage layer. The gap is in what happens before data goes into the PIM (mapping, normalization, enrichment) and what happens after it goes out (channel-specific transformation, syndication, and validation). Bolting a shiny new AI tool onto an unresolved data infrastructure problem is like putting a spoiler on a car with flat tires. It won’t make you go any faster.
What the Winning Architecture Looks Like
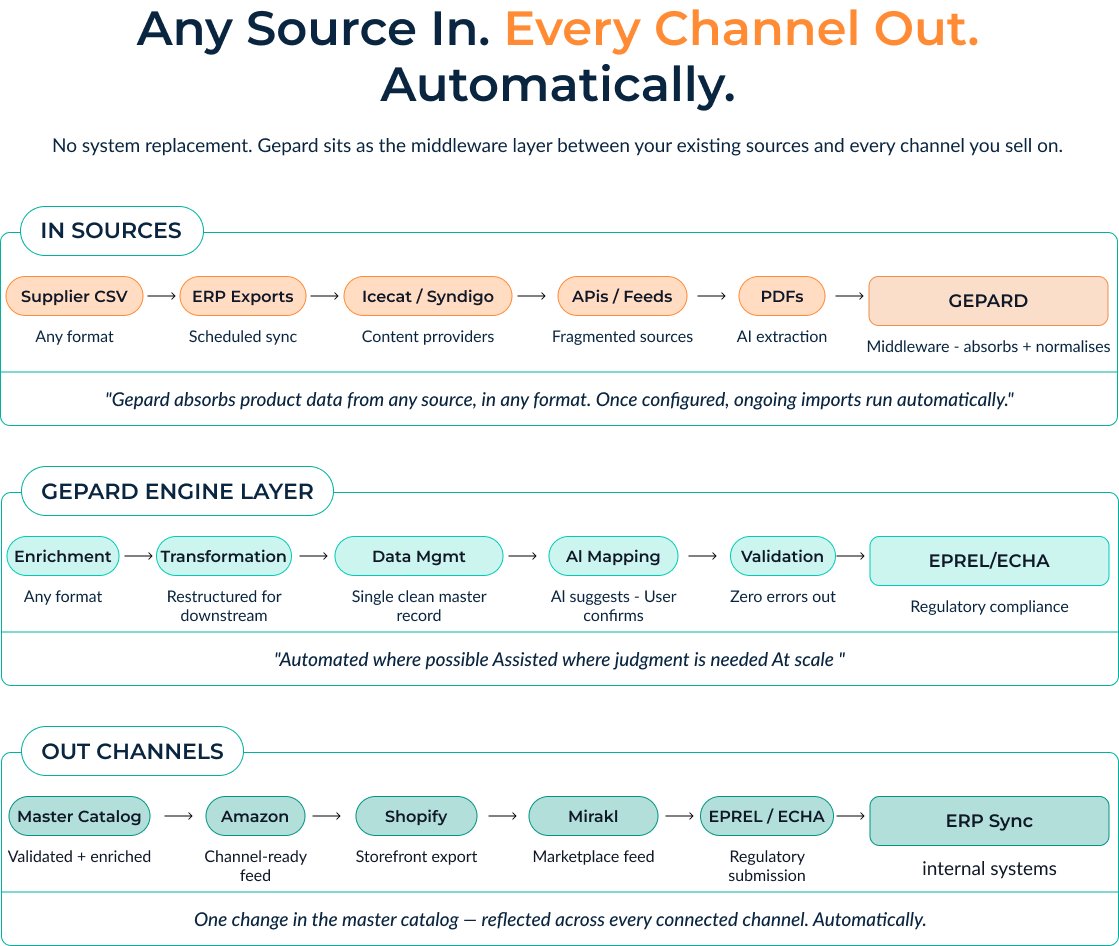
So, how are the winners doing it? They aren’t ripping and replacing their ERPs or PIMs. Instead, they are deploying a specialized middleware architecture that sits perfectly between their existing core systems and all external channels.
This winning architecture relies on a strict, automated three-stage data flow:
- IN: The system absorbs data from any source, in any format (API, EDI, CSV, PDF). It is configured once to understand the unique quirks of each supplier, instantly centralizing the chaos.
- THROUGH: This is where the heavy lifting happens. The data undergoes automated enrichment, AI-assisted taxonomy mapping, strict validation against your rules, and normalization at scale. Weights and measures are standardized; missing attributes are flagged.
- OUT: Once the data is pristine, a single master catalog change automatically transforms and propagates to every connected channel – Shopify, Amazon, regional marketplaces – adhering perfectly to each platform’s unique requirements.
This architectural shift moves you from defense to offense. You can dive deeper into how to structure this data flow during the scheduled Gepard Demo to see exactly how this middleware model operates in the wild.
The Role of AI in a Data-First Approach
This brings us to a crucial misconception about AI in retail operations. AI should not be an autonomous black box running wild in your catalog. In a data-first approach, AI is strictly assistive. It is a copilot that scales your team’s expertise.
Good data infrastructure makes AI assistants reliable. When the underlying system is sound, AI can do incredible things for your operational efficiency:
- Smart Mapping: AI suggests complex taxonomy mappings between a supplier’s weird category names and your clean internal structure. Humans simply review and confirm, reducing manual work by 90% without sacrificing control.
- Content Enrichment: AI fills in content gaps, flags incomplete attributes before they go live, and generates localized, channel-specific descriptions based on hard data points.
- Unstructured Data Extraction: AI can pull structured attributes out of flat supplier PDFs or promotional images, turning dead files into searchable data.
The honest point to remember: AI performs predictably and safely only when the catalog it draws from is clean, consistent, and structured.
What ROI Actually Looks Like (Operational First, Revenue Downstream)
When you fix the data layer, the return on investment doesn’t just show up as a vague promise of “better brand equity.” It hits your P&L in two distinct, measurable lanes.
The first lane is immediate operational savings. By automating the “IN” and “THROUGH” stages, you drastically accelerate supplier onboarding. What used to take weeks of manual content ops workload now takes hours. You can launch new channels and enter new markets faster than your competitors can format their Excel columns. You are simply doing more with the headcount you already have.
The second lane is downstream revenue impact. This is where the initial promise of AI finally materializes. Because your catalog is now rich, clean, and normalized, your AI search and recommendation engines actually work. Product discovery becomes intuitive. Customers find exactly what they are looking for, leading to higher conversion rates and fewer returns.
The key takeaway is that the first wins are in the workflows that are already costing you time and money today. The massive revenue gains follow naturally from a cleaner catalog. You can see how this two-lane ROI plays out for enterprise brands by reading our detailed e-commerce case studies.
The Build-vs-Buy Question (And Why It Usually Resolves Itself Quickly)
For enterprise engineering teams, the instinct is often to build this connective tissue in-house. “It’s just mapping data,” they say.
But internal tools only solve yesterday’s problem. Scale changes the equation entirely. When you are dealing with millions of SKUs, constant API changes from marketplaces like Amazon, and suppliers changing their feed formats without warning, an internal script quickly turns into a massive technical debt nightmare.
Consider the sheer volume: a robust platform processes upwards of 120 million product updates per month across 15+ countries, with AI built into the syndication logic from day one. The maintenance burden of building and supporting an equivalent internal system will drain your engineering resources away from your actual core product.
In our experience, the build-vs-buy question usually resolves itself immediately when technical leaders see how fast they can be live and syndicating data with a dedicated platform, versus spending the next 18 months trying to build a lesser version of it internally.
Conclusion
Let’s return to the opening premise. When you leave ShopTalk and head back to your desk, remember that the retailers winning on AI aren’t using better models. They are using better data.
The competitive moat in AI-powered retail isn’t the AI itself. Anyone can license an LLM. Anyone can buy an off-the-shelf semantic search tool. Your true, defensible moat is the data infrastructure underneath it. It is the plumbing that ensures your AI is fed with the richest, most accurate, and most beautifully structured product data in your vertical.
Stop letting messy supplier feeds break your expensive AI initiatives. Get the infrastructure right.
Ready to see what your AI can do with properly structured data? Try a free account at gepard.io. There is no credit card required; you can test it with up to 200 products, and all our AI tools are included.